
1个AI天才值1亿美元?Meta抢人不是疯,45年前一篇论文早算清了
1个AI天才值1亿美元?Meta抢人不是疯,45年前一篇论文早算清了Meta曾被曝出向OpenAI研究员开出「1亿美元量级」薪酬包。奥特曼在播客里曝出这个数字时,硅谷一度怀疑自己听错了。普通博士后年薪不过5万美元,顶尖研究员年薪据报道超过1000万美元:差距接近200倍。这个数字背后,是45年前一篇经济学论文早已算清的逻辑。
来自主题: AI资讯
7576 点击 2026-05-30 10:04
 搜索
搜索
Meta曾被曝出向OpenAI研究员开出「1亿美元量级」薪酬包。奥特曼在播客里曝出这个数字时,硅谷一度怀疑自己听错了。普通博士后年薪不过5万美元,顶尖研究员年薪据报道超过1000万美元:差距接近200倍。这个数字背后,是45年前一篇经济学论文早已算清的逻辑。
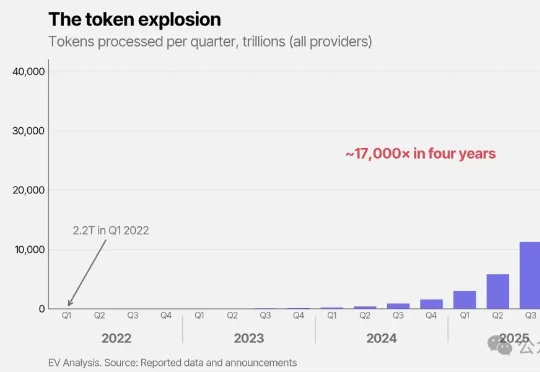
Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。
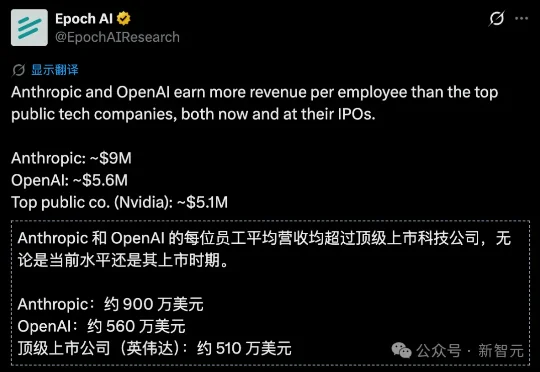
Epoch AI最新数据:Anthropic人均年营收900万美元,远超OpenAI的560万和英伟达的510万。一家没上市的AI公司,人效已刷新硅谷全部历史纪录。
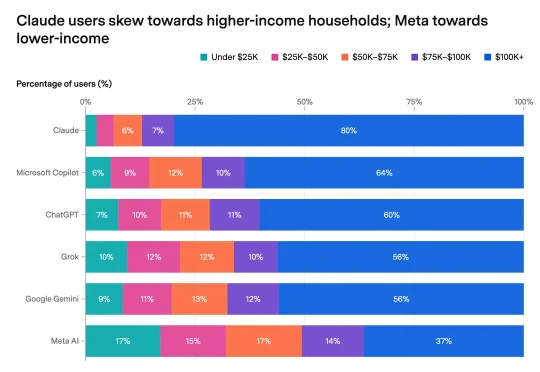
Epoch AI 与 Ipsos 调查显示,美国 Claude 周活用户 80% 来自年入 10 万美元以上家庭。AI 助手开始按价格、入口和工作场景分层,高收入用户率先进入更高阶的 AI 服务。

Epoch AI最新调研:一半美国成年人上周用过AI,但真正的分水岭不是技术——是谁在付钱。公司掏钱的那一刻,AI工作使用率从38%直接飙到76%。

2025 年 9 月,The Information 报道 Anthropic 曾讨论在接下来一年内投入超过 10 亿美元用于 RL 环境建设。Epoch AI 最近发了一篇报告,采访了 18 位来自 RL 环境初创公司、neolab(Cursor 这类应用型 AI 公司)和前沿实验室的从业者
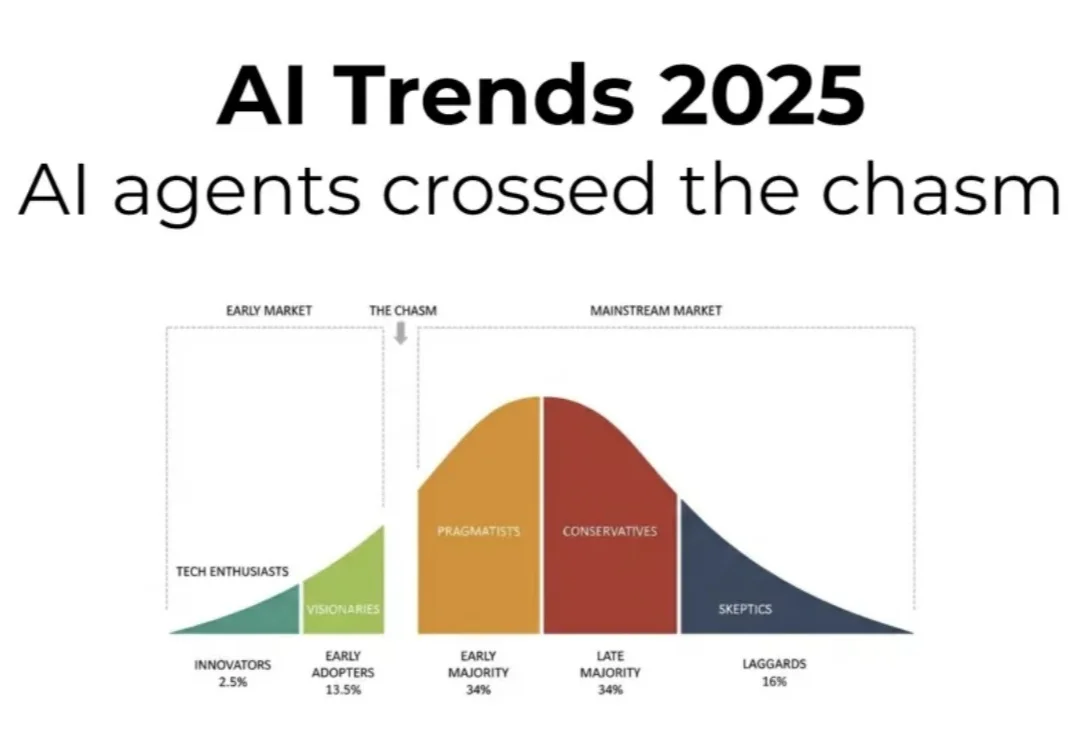
2025 年,AI 智能体“跨过了鸿沟”,开始被更广泛、务实的用户群体采用,不再只是少数发烧友或愿景家在用。
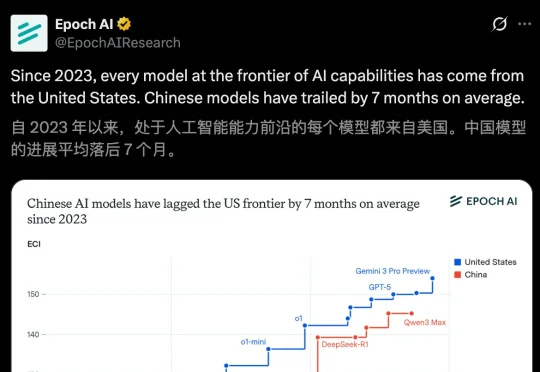
一张来自Epoch AI图表给出了一个冷静却尖锐的结论:中国AI平均落后7个月。一张图揭示真相:自2023年以来,前沿AI全部来自美国!最近,Epoch AI一份报告指出,中国AI模型的进展平均落后于美国7个月——最小差距为4个月,最大差距为14个月。

Epoch AI年终大盘点来了!出乎意料的是,AI没有停滞,反而变快了。
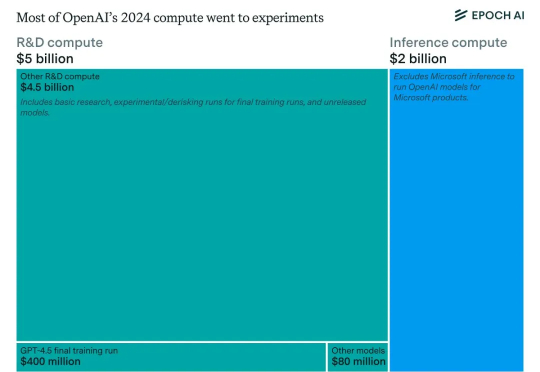
来扒一扒OpenAI算力支出的天价账单——据Epoch AI统计的数据显示,去年OpenAI在计算资源上支出了70亿美元。由于公司当时还没有大量的算力,所以这笔天价账单基本都是以向微软租用云算力的形式支付出去的,并不包括对数据中心的前期投入。